Accélérer sans casser : retour d'expérience côté produit
 Auteur
Jean-François, CTO
Auteur
Jean-François, CTO

Il y a 10 mois, on mettait en production environ 45 évolutions produit par semaine. Aujourd’hui, on est autour de 90. Avec un développeur en moins.
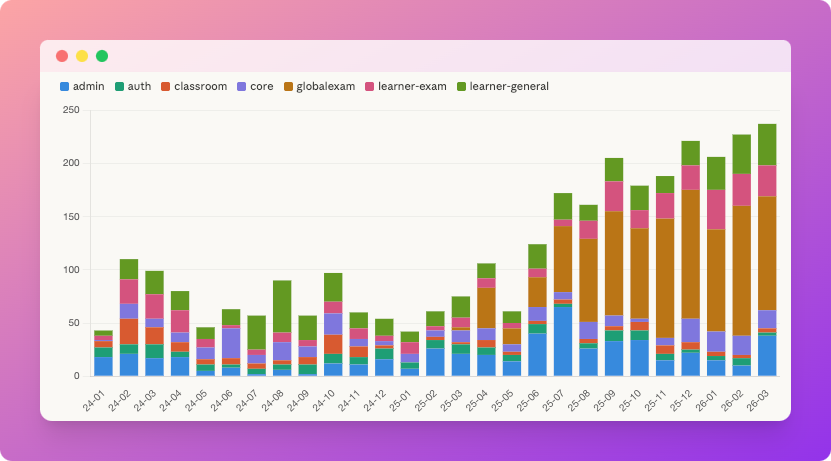 Volume hebdomadaire de pull requests mergées, ventilé par périmètre produit. La marche est nette à partir de l’été 2025.
Volume hebdomadaire de pull requests mergées, ventilé par périmètre produit. La marche est nette à partir de l’été 2025.
Dans le même temps, le délai entre le moment où une amélioration est prête et celui où elle arrive en production a fortement baissé :
- en moyenne, on est passé de 19 jours à moins de 3 jours
- notre merge time est désormais de 8 heures
Et surtout : on n’a pas dégradé la qualité de service.
Je vais essayer de raconter comment on en est arrivés là, sans trop embellir. Certaines choses ont marché parce qu’on a insisté, d’autres parce qu’on a eu de la chance, quelques-unes par hasard. Je ne crois pas qu’on ait découvert une recette. Mais quand je regarde en arrière, il y a des décisions qui ont vraiment compté.
Pourquoi ces chiffres, ça change quoi
Avant d’entrer dans le détail, je crois qu’il faut dire un truc : doubler le nombre de mises en production ne veut pas dire qu’on a doublé la valeur livrée aux utilisateurs. Ce serait trop simple.
Quand on livre tous les quinze jours, chaque livraison est un événement. On prépare, on coordonne, on stresse un peu, on regroupe les changements pour rentabiliser le déploiement. Quand on livre plusieurs fois par jour, la mise en production devient un non-événement. C’est juste un truc qui se passe.
Concrètement, les bugs se détectent plus vite, parce qu’ils arrivent isolés. Quand vingt changements partent ensemble et qu’un comportement bizarre apparaît, il faut enquêter. Quand un seul changement part et qu’un comportement bizarre apparaît, on sait à peu près où regarder.
Les retours en arrière deviennent triviaux aussi. On ne revient pas sur “le déploiement de mardi”, on revient sur ce changement précis. C’est tout.
Et puis les développeurs gardent le contexte de ce qu’ils ont écrit. Personne ne corrige correctement du code qu’il a écrit il y a trois semaines, en se rappelant clairement de ses intentions. C’est probablement le bénéfice le plus sous-estimé.
Ce qu’on a changé
On n’a pas trouvé d’outil magique. On a enlevé progressivement ce qui ralentissait.
Quatre changements ont vraiment compté. Aucun n’est spectaculaire pris isolément. C’est leur combinaison qui produit l’effet.
1. On a arrêté de laisser traîner les évolutions en cours
Aujourd’hui, une évolution qui reste ouverte (sans être livrée à l’utilisateur) plus d’une semaine est fermée automatiquement.
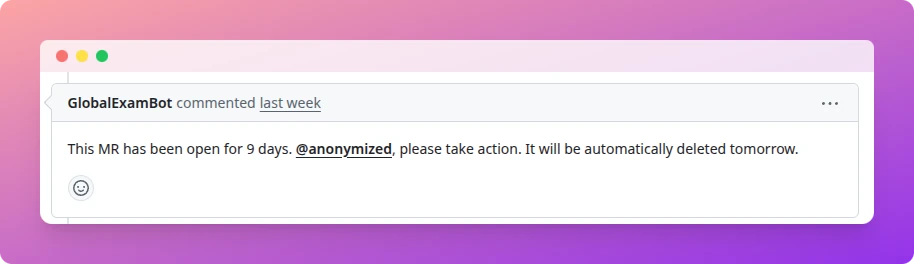 Le rappel automatique envoyé sur les merge requests trop anciennes. Au bout de 9 jours, c’est le dernier avertissement avant fermeture.
Le rappel automatique envoyé sur les merge requests trop anciennes. Au bout de 9 jours, c’est le dernier avertissement avant fermeture.
On n’a pas commencé là. Au début, c’était 4 semaines. Puis 3. Puis 2. Puis 1.
Cette progression a été essentielle. Si on avait imposé une semaine d’entrée de jeu, je pense que l’équipe se serait braquée, et à raison : on aurait fermé en masse des sujets parfaitement légitimes. À chaque palier, on a laissé le temps aux habitudes de s’adapter, puis on a resserré.
Ce qui a vraiment changé, c’est trois choses.
D’abord, on a appris à travailler sur des sujets plus petits. Un changement qu’on doit livrer en moins d’une semaine ne peut pas être une refonte. Donc on découpe. Et on apprend à découper, ce qui n’est pas une compétence évidente.
Ensuite, on donne du feedback plus vite. Une revue qui traîne devient un risque concret : si je ne relis pas la PR de mon collègue dans les jours qui viennent, elle va se faire fermer. La revue est passée d’arrière-plan à premier plan dans la journée de chacun.
Enfin, les sujets “en attente” ont disparu. Les “je verrai plus tard quand j’aurai du temps” n’existent plus. Soit le sujet est assez important pour être terminé maintenant, soit il ne l’est pas et il est fermé. Le purgatoire technique n’existe plus.
Bénéfice secondaire qu’on n’avait pas anticipé : la taille du backlog technique invisible a fondu. Tous ces “presque finis” qui dormaient dans les branches et qu’on ne reverrait jamais, ils ne sont plus là.
Ce que ça a coûté
Honnêtement, une partie de l’équipe a vécu ça comme une violence au début. Fermer le travail de quelqu’un, même s’il est inachevé, c’est un signal fort. Plusieurs choses ont aidé à le faire passer.
Le bot prévient plusieurs jours avant la fermeture. Il n’y a pas de surprise.
On peut toujours rouvrir une branche, reprendre le travail. La fermeture n’efface rien, elle range.
Et on a explicité la règle collectivement. Ce n’est pas une sanction individuelle, c’est une mécanique pour garder le système fluide. Le bot ne juge personne. Il a une règle, il l’applique.
Aujourd’hui, plus personne ne remet la règle en question. Mais il a fallu plusieurs mois pour en arriver là, et je ne suis pas sûr qu’on aurait tenu si on avait pris des raccourcis sur l’accompagnement.
2. On a massivement adopté l’IA
Au départ, l’équipe était très réfractaire.
Et les raisons étaient bonnes, je dois le dire : qualité du code généré inégale, peur d’une dépendance à un outil, scepticisme légitime sur la valeur réelle au-delà du buzz. On n’a forcé personne. On a juste laissé du temps, partagé des cas d’usage concrets, et organisé quelques moments où les plus convaincus montraient ce qu’ils faisaient au quotidien.
Petit à petit, l’usage s’est installé. Aujourd’hui, tout le monde l’utilise.
Pas seulement les développeurs. Les chefs de produit s’en servent pour structurer des specs, reformuler des besoins, préparer des analyses. Les designers itèrent plus vite sur des variantes, génèrent des contenus de test, écrivent des micro-copies.
Ce qui prend beaucoup moins de temps qu’avant : écrire et améliorer du code, surtout sur la relecture, le refactoring, l’exploration d’une base qu’on ne connaît pas. Structurer des idées, passer d’une note brute à un plan clair. Documenter, parce que la barrière qui empêchait beaucoup de docs d’exister est tombée.
Ce que l’IA n’a pas remplacé
Il y a un point important à dire, parce que je vois beaucoup de discours flous là-dessus. L’IA n’a pas remplacé la réflexion produit, ni les décisions d’architecture, ni les conversations difficiles. Elle a libéré du temps sur des tâches mécaniques, et ce temps libéré a été réinvesti sur des tâches qui demandent vraiment du jugement.
C’est ce qu’on espérait. Mais ce n’était pas du tout évident a priori, et il y a un risque inverse qui est réel : que l’équipe se mette à produire en masse du contenu peu réfléchi parce que c’est plus facile. On surveille ce risque activement.
Pour ça, on a mis en place un suivi explicite de la satisfaction sur les contenus générés par IA.
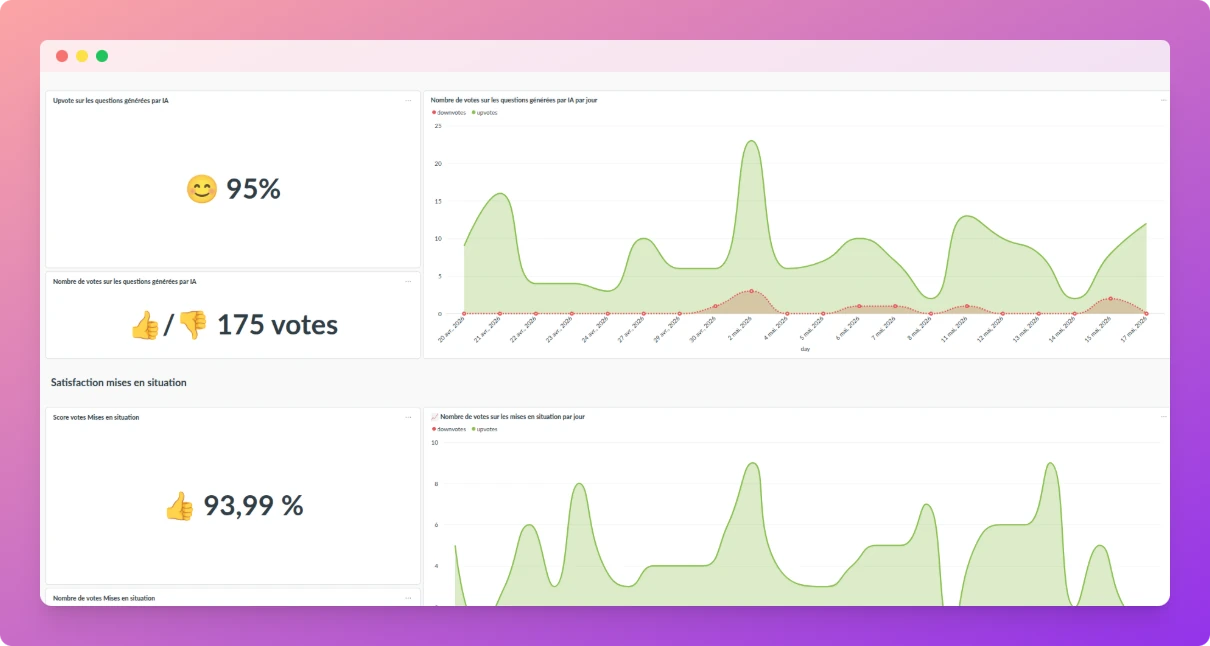 Notre dashboard de satisfaction sur les contenus générés par IA. Plus de 95 % d’avis positifs sur les questions, près de 94 % sur les mises en situation, mesurés sur des centaines de votes utilisateurs.
Notre dashboard de satisfaction sur les contenus générés par IA. Plus de 95 % d’avis positifs sur les questions, près de 94 % sur les mises en situation, mesurés sur des centaines de votes utilisateurs.
Ces chiffres ne sont pas anodins. Ils nous disent que la qualité tient, et qu’on peut continuer à étendre l’usage. Si le score s’effondrait, ce serait un signal fort que l’IA est devenue un raccourci plutôt qu’un levier. Pour l’instant, ça tient. Je ne fais pas de pari sur la suite, mais je regarde de près.
3. On a changé notre manière de livrer
On a mis en place des mécanismes qui permettent d’activer ou non une fonctionnalité facilement, et de livrer en continu.
Concrètement, merger du code et activer une fonctionnalité pour les utilisateurs sont devenus deux décisions séparées. Avant, livrer un code voulait dire le rendre actif. Maintenant, on peut livrer du code “dormant”, l’activer pour un petit pourcentage d’utilisateurs, observer, puis élargir ou retirer.
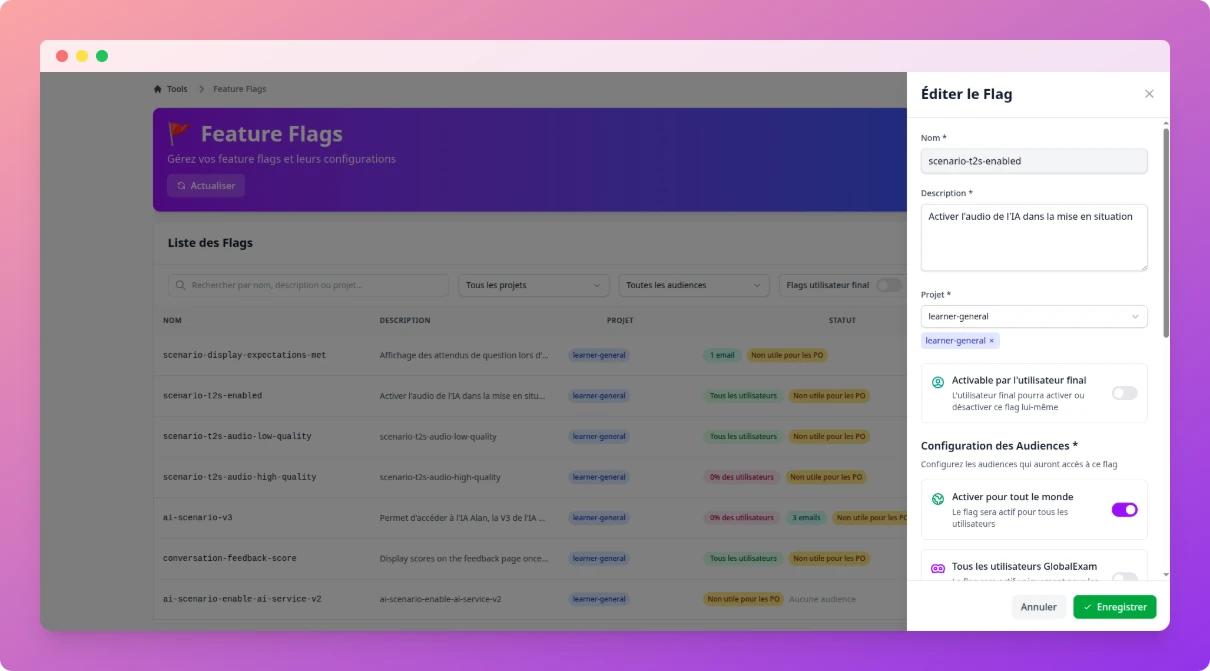 Chaque micro-fonctionnalité peut être activée pour une personne précise, un type de visiteur, un pourcentage d’utilisateurs…
Chaque micro-fonctionnalité peut être activée pour une personne précise, un type de visiteur, un pourcentage d’utilisateurs…
Cette séparation change beaucoup de choses.
Les gros chantiers peuvent vivre en production. Une refonte qui prend trois semaines n’a plus besoin d’attendre la fin pour être mergée. Elle vit en production, derrière un drapeau, et se construit par petits incréments visibles uniquement de l’équipe.
Les expérimentations deviennent peu coûteuses. Activer une nouveauté pour 5 % des utilisateurs, regarder la réaction, ajuster, étendre, c’est devenu un mode de travail normal.
Et les retours en arrière sont instantanés. Si un signal négatif apparaît après l’activation, on désactive en quelques secondes, sans déploiement.
Résultat : plusieurs centaines de mises en production par mois, avec une équipe d’une dizaine de développeurs. On ne regroupe plus les changements en gros lots. On livre en continu, par petits incréments.
Le piège dans lequel on est tombés
Il y a un piège dont je dois parler, parce qu’on est tombés dedans avant de comprendre.
La tentation, quand on met en place ces mécanismes, c’est de les utiliser comme une nouvelle forme de procrastination. On garde des fonctionnalités “presque prêtes” derrière un drapeau pendant des mois, en se disant qu’on les activera plus tard. Le drapeau devient un cimetière.
La règle d’auto-fermeture évoquée plus haut nous protège en partie : un drapeau qui ne sert pas finit par disparaître. Mais ça demande une discipline réelle. On a régulièrement des phases de “nettoyage des drapeaux” pour éviter qu’ils ne deviennent une dette en eux-mêmes. Ce n’est pas glamour, mais c’est nécessaire.
4. On a créé une boucle de feedback très courte
On a volontairement poussé les équipes à utiliser davantage le produit.
Avec des mécaniques toutes bêtes : des challenges internes, des sessions où l’équipe utilise le produit dans des conditions proches de celles des utilisateurs réels. Des petits rituels où chacun raconte ce qu’il a vu en utilisant l’application.
Le but n’est pas le dogfooding comme exercice de style. C’est de remettre les personnes qui construisent le produit en contact direct avec l’expérience qu’elles construisent. Ça change la qualité des conversations en réunion : on parle de choses concrètes qu’on a vues, pas de choses abstraites qu’on imagine.
Côté produit, on a multiplié les points de collecte de signaux. Des retours utilisateurs très simples (pouce en l’air, pouce en bas) à plusieurs endroits de l’application. Un suivi très rapproché de ces signaux.
 Le widget de feedback intégré directement dans l’application. Deux clics, pas de formulaire, pas de friction. Le coût pour l’utilisateur est presque nul, ce qui maximise le volume de signal récolté.
Le widget de feedback intégré directement dans l’application. Deux clics, pas de formulaire, pas de friction. Le coût pour l’utilisateur est presque nul, ce qui maximise le volume de signal récolté.
L’objectif est simple : détecter vite, corriger vite.
Ce que je trouve intéressant avec un signal aussi basique qu’un pouce, c’est qu’il n’a pas besoin d’être individuellement fiable. Un utilisateur qui clique sur “pouce en bas” parce qu’il était de mauvaise humeur ne casse rien. Ce qui compte, c’est la tendance. Si le ratio se dégrade brutalement sur un segment, on a un signal exploitable en quelques heures, pas en quelques semaines.
C’est complémentaire d’un système de retour qualitatif plus lourd (entretiens, support utilisateurs), pas un remplacement. Mais c’est un système qu’on peut consulter tous les matins en deux minutes. Ça change la fréquence à laquelle on regarde ce qui se passe.
Le coût caché des feedbacks compliqués
Une part importante de notre stratégie de feedback, c’est de minimiser ce qu’on demande aux utilisateurs. Pas de formulaires multi-pages, pas de NPS bimensuels, pas de pop-ups intrusives. Deux boutons.
Le coût d’un feedback est inversement proportionnel à son volume. Plus c’est cher pour l’utilisateur de répondre, moins on a de réponses, et plus elles sont biaisées (typiquement vers les gens très contents ou très mécontents). Garder le coût au minimum, c’est ce qui permet d’avoir un signal représentatif plutôt qu’extrême.
Ce que ça change côté utilisateur
Ce n’est pas la vitesse qui compte. C’est ce qu’elle permet.
Si on doublait le rythme uniquement pour cocher des cases, ce serait inutile, voire contre-productif. La vraie question, c’est : qu’est-ce qu’on peut faire pour les utilisateurs qu’on ne pouvait pas faire avant ?
Aujourd’hui, ça se traduit par plus de nouvelles fonctionnalités. On peut tenter des choses qu’on n’aurait pas tentées avant, parce que le coût d’essai a baissé.
Plus d’améliorations du quotidien aussi. Les petites frictions, un libellé peu clair, une interaction maladroite, un parcours mal calibré, sont traitées en quelques heures au lieu d’attendre un trimestre de “polish”.
Et des corrections plus rapides. Quand un bug apparaît, le temps entre le signalement et la correction en production est devenu très court.
Tout ça sans instabilité supplémentaire. C’est le point sur lequel on a été le plus vigilant. La promesse “on va plus vite” est vide si elle s’accompagne d’une dégradation de la fiabilité. Nos indicateurs d’incidents, de temps de résolution, de plaintes utilisateurs sont restés stables ou se sont améliorés sur la même période.
Ce qu’on a perdu, aussi
Je veux être honnête sur ce qu’on a perdu, parce que sinon ce billet sonne faux.
On a perdu le moment “grand-messe” des releases. Quand on regroupait les changements, il y avait un effet d’annonce. Aujourd’hui, les choses arrivent en continu, et il faut faire un effort de communication explicite pour raconter ce qu’on a livré, parce que personne ne le voit autrement. Ça paraît anodin, mais ça représente un vrai travail de visibilité qu’on n’avait pas avant.
On a aussi perdu une certaine forme de réflexion lente. Quand on a deux semaines avant la prochaine release, on prend le temps. Quand on peut livrer dans l’heure, on est tenté de raccourcir la phase de réflexion. On compense par d’autres rituels (revues d’architecture, design docs), mais c’est un effort conscient, pas une conséquence naturelle.
Et on a perdu l’illusion du contrôle absolu. Livrer en gros lots donne l’impression de maîtriser. C’est une illusion (les bugs arrivent quand même) mais c’est confortable. La livraison continue oblige à accepter qu’on ne peut pas tout vérifier avant, et qu’il faut investir dans la capacité à détecter et corriger après. Pour certains profils, ce changement de mentalité est très difficile.
Ces compromis valent largement le coup pour nous. Mais ils existent, et je préfère les nommer.
Ce qu’on retient
Accélérer n’est pas le plus compliqué.
Le faire sans dégrader la qualité demande de raccourcir les cycles. Pas juste les délais affichés, mais tous les temps cachés (revue, attente, validation). Ça demande aussi de multiplier les feedbacks, humains et automatiques, qualitatifs et quantitatifs, internes et utilisateurs. Et ça demande de garder des garde-fous simples, peu nombreux, automatisés autant que possible.
On n’a rien révolutionné. On a juste rendu le système plus fluide.
Ce qui n’est probablement pas transposable
Je voudrais éviter de finir sur une note “voilà la recette, copiez-collez”, parce que ce serait malhonnête.
Beaucoup de ce qu’on a fait dépend d’un contexte spécifique : la nature de notre produit, la taille de notre équipe, la culture qui existait déjà, le type d’utilisateurs qu’on sert. Quelqu’un qui travaille sur un logiciel embarqué dans un dispositif médical n’a pas les mêmes contraintes que nous, et c’est tant mieux.
Ce qui est probablement transposable, c’est la direction générale : raccourcir, observer, ajuster, automatiser les garde-fous. La mise en œuvre concrète doit être réinventée à chaque contexte.
Et surtout, ça prend du temps. Les 10 mois qu’on a derrière nous ne se résument pas à “on a décidé d’accélérer”. Ils se résument à une centaine de petites décisions, dont plusieurs auraient pu rater. On a beaucoup appris en faisant. Et on a eu de la chance aussi, sur certains points.
Si je devais refaire le chemin aujourd’hui, je ne sais pas si je referais exactement les mêmes choix. Mais je sais que je referais le même genre de mouvement : enlever ce qui ralentit, plutôt que chercher à ajouter ce qui accélère. C’est presque toujours plus efficace, et beaucoup moins stressant pour tout le monde.